由一次kafka消费端消息阻塞问题分析kafka消费端线程模型
最近线上有个需求希望能停止kafka消费某个topic一段时间,结果导致将该系统消费的所有topic都阻塞掉了。
背景介绍
首先介绍下该系统consumer的配置,该系统启动了一个ConsumerConnector,使用1个group同时消费3个topic,每个topic分配了一定数量的消费线程。改造的方案是在消费线程每次调用hasNext方法获取消息前,通过一个动态配置控制线程sleep一段时间。发布上线后推送配置关闭其中1个topic的时候,通过监控发现,其他所有的3个topic全部都停止了消息消费,回滚了配置后,所有topic才又开始继续消费。为什么一个topic的消费线程sleep,会影响所有topic的消息消费呢?
问题排查定位过程
根据当时情况想到的几种可能:一个是开关逻辑有bug,原本一个开关控制一个topic的情况变成一个开关控制所有topic是否消费了,通过日志以及jstack线程快照很快排除了这一点,开关逻辑确认没有bug;再就是怀疑kafkaconsumer的client内部是不是有什么内存缓冲队列之类的东西导致阻塞了其他的topic,为了验证这一点,我们获取了当时异常期间的线程快照,以及kafkaclient的源码。
首先来看线程快照中其他topic的消费线程堆栈:
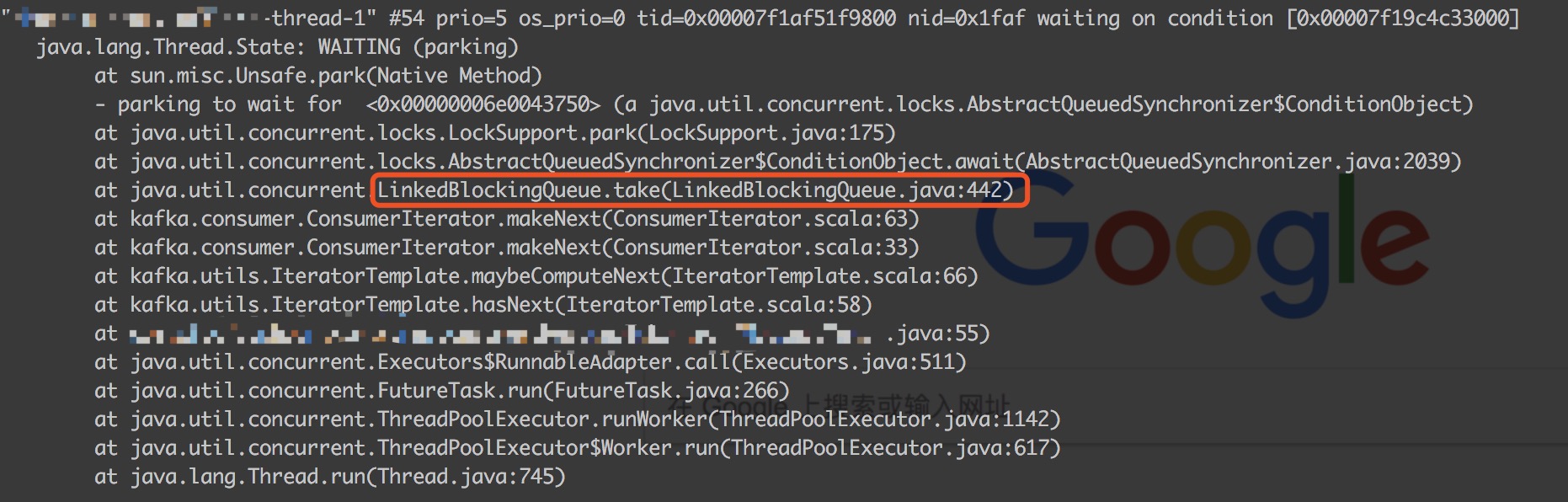
根据线程名称,发现我们创建的消息消费线程停在了hasNext方法上,便排除了开关逻辑bug,更深的堆栈发现消费线程阻塞在了LinkedBlockingQueue的take方法上,说明该队列中已无消息,既然hasNext方法是从一个LinkedBlockingQueue上获取消息,那么也就是说kafka一定是有单独的线程来拉取消息然后put到这个LinkedBlockingQueue的,根据经验,一般第三方组件内线程都会设定特定名字,或者能从堆栈中一些第三方包路径找到第三方组件的涉及的线程堆栈,于是便找到了下面的堆栈:
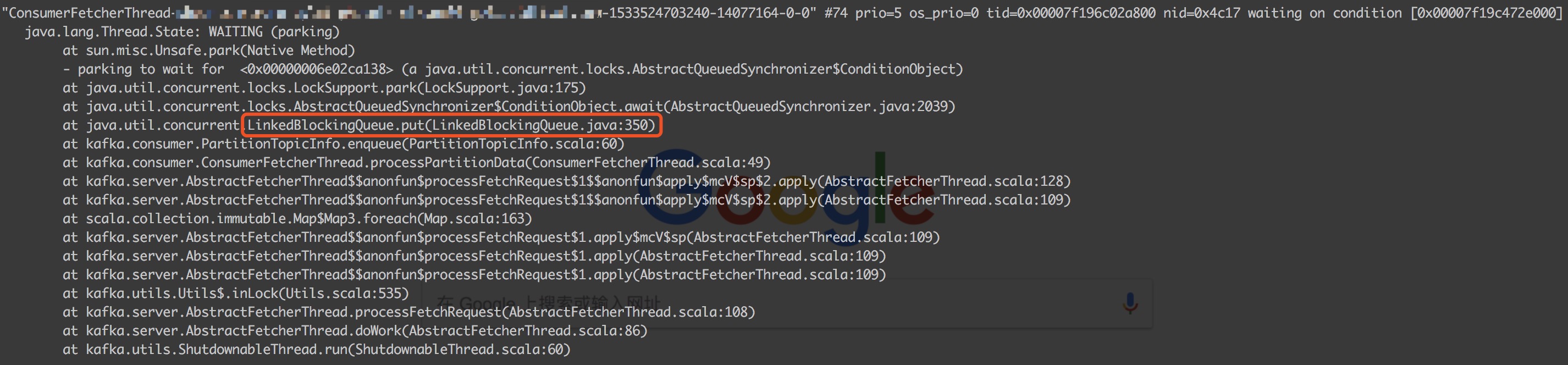
发现有个ConsumerFetcherThread阻塞在了LinkedBlockingQueue的put方法上。消费线程阻塞在take方法,这里阻塞在put方法,说明这还不是同一个LinkedBlockingQueue。
为了搞清楚这两个LinkedBlockingQueue到底都是做什么的,便需要通过源码来查看了,下载对应版本的kafka的源码,跟踪kafka源码还需要下载scala还有gradle,还有idea的scala插件。在阻塞线程的线程堆栈的指引下,对源码进行跟踪排查:
消费线程阻塞相关代码:
|
|
|
|
makeNext方法会从channel取出一个FetchedDataChunk,放入本地变量current中,每次获取元素再优先从current上获取,一个FetchedDataChunk内部包含了多条消息,这里消费线程阻塞在makeNext方法的channel.take处,这个channel是ConsumerIterator构造方法传入的,找到创建ConsumerIterator的地方
|
|
这个队列是在创建KafkaStream时传入的,需要看下KafkaStream如何创建,从createMessageStreams方法看起
|
|
|
|
topicThreadIds的key是topic,value是根据消费线程数量产生的对应大小的集合,根据topicThreadIds创建了queuesAndStreams,queuesAndStreams的ket是topic,value是消费线程对应的KafkaStream集合,一个消费线程对应一个KafkaStream,一个KafkaStream对应一个LinkedBlockingQueue,大小由queued.max.message.chunks参数指定,默认是2,也就是说各个消费线程hasNext方法阻塞逻辑使用的队列是相互隔离的。继续往下看,registerConsumerInZK方法主要是将消费者相关信息注册在zk上,reinitializeConsumer方法初始化具体的consumer。
|
|
reinitializeConsumer方法首先创建了一些用于负载均衡超时等相关逻辑的zk监听;然后根据topicThreadIds和queuesAndStreams创建了topicThreadIdAndQueues,topicThreadIdAndQueues的key是topic+线程号组成的key,value是线程对应的KafkaStream里的LinkedBlockingQueue;然后注册了zk监听;最后通过syncedRebalance做第一次的初始化动作
|
|
|
|
主要关注currentTopicRegistry的初始化相关逻辑,topicPartitions是从zk上获取到了当前机器分配到的所有partition分区,通过topicPartitions来创建currentTopicRegistry,currentTopicRegistry的key是topic,value是个map,key是partition,value是PartitionTopicInfo,PartitionTopicInfo包含了topic,partition,消费线程对应的LinkedBlockingQueue,还有一些offset等信息。看核心的updateFetcher方法
|
|
根据TopicRegistry创建allPartitionInfos,allPartitionInfos是所有PartitionTopicInfo的列表,然后开始连接逻辑
|
|
创建LeaderFinderThread线程用于开启连接,然后将之前的allPartitionInfos转化成partitionMap,partitionMap的key是topic+partitionId,value是PartitionTopicInfo,这个partitionMap在后面有用处,看下LeaderFinderThread的逻辑
|
|
通过ClientUtils.fetchTopicMetadata方法获取kafka相关元信息数据,主要看addFetcherForPartitions方法
|
|
BrokerAndFetcherId由broker和一个拉取线程号组成,拉取线程数量通过num.consumer.fetchers参数控制,默认为1,即一个broker有1个拉取线程,相当于默认kafka会创建broker数量个拉取线程,用于从broker处拉取消息,创建拉取线程见createFetcherThread
|
|
可以看到线程名字是ConsumerFetcherThread,之前看到线程堆栈的就是这里的线程阻塞在了put方法上,接下来根据线程堆栈的信息往下看
|
|
partitionMap的key是topic+partitionId,value是PartitionTopicInfo,这里将所有的topic,partition还有offset和拉取消息数量,传入fetchRequestBuilder,创建了一个FetchRequest
|
|
通过simpleConsumer.fetch(fetchRequest)方法向当前这一台broker拉取一批消息,一次请求会拉取当前consumer所需要的所有topic所有partition下的一组消息,response.data的key是topic+partition,value是对应的一组消息,看processPartitionData方法
|
|
从partitionMap根据topicAndPartition获取PartitionTopicInfo
|
|
调用PartitionTopicInfo.enqueue方法将这个topicAndPartition下的一组消息添加到chunkQueue这个队列中,这个队列就是创建KafkaStream时创建的LinkedBlockingQueue了。
kafka线程模型
根据对线程堆栈以及源码的分析,了解了kafka的线程模型:
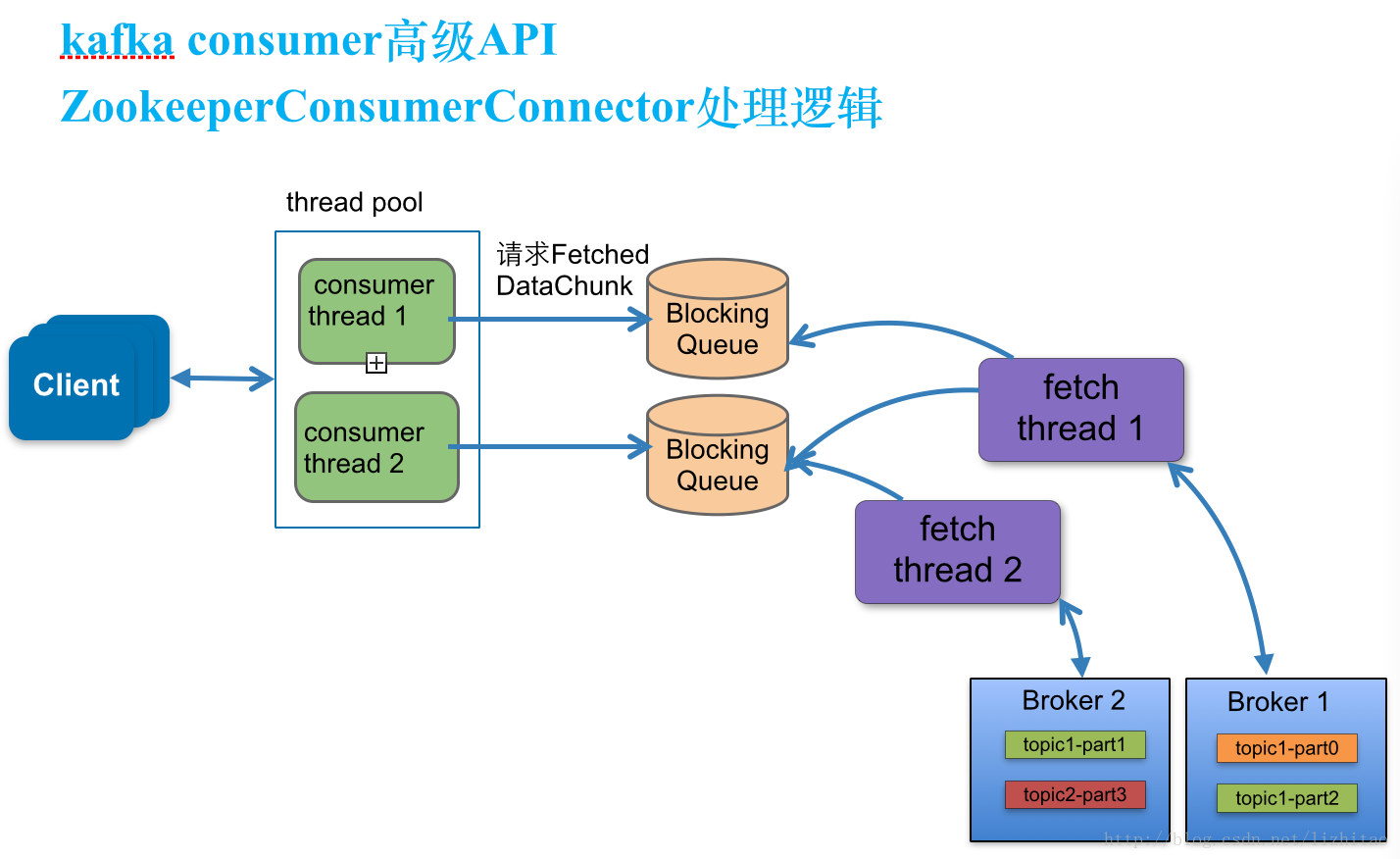
消息消费侧:kafka每个消费线程会处理一个topic的部分partition,对应着一个kafkaStream,每个kafkaStream对应一个LinkedBlockingQueue缓存消息,每次消费线程消费消息时会从对应队列中获取消息;
消息拉取侧:kafka会根据broker数量和num.consumer.fetchers参数创建若干消息拉取线程,用于连接broker并拉取消息,然后填充到各消费线程对应的LinkedBlockingQueue上。
两侧的线程通过LinkedBlockingQueue进行连接。
所以建议不要将处理时间太长的业务,直接放在kafka消费线程上去处理,容易阻塞其他topic,可以投递到后端业务处理线程池去处理消息,或者可以将处理时间太长的业务单独使用一个ConsumerConnector,从而在topic维度完全隔离资源。
结论
kafka的每个消息拉取线程每次会拉取所有topic的消息,put到一个队列中,当我们sleep一个topic的消费线程时,该topic对应的LinkedBlockingQueue队列中的数据得不到消费线程take,很快就满了,消息拉取线程拉取到消息向各个topic对应的LinkedBlockingQueue添加消息的时候,当向该停止消费的topic的LinkedBlockingQueue进行put的时候发现队列满了就会阻塞住,影响了向其他topic对应的LinkedBlockingQueue进行put了,所以其他topic也获取不到消息了。最终所有的拉取线程全部都阻塞在停止消费的这个topic对应队列的put方法上了。
解决
一个topic使用一个ConsumerConnector,那么就在消息拉取线程上做到了topic维度的完全隔离,就可以使用在消费线程sleep这种停止消费方案了。